Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
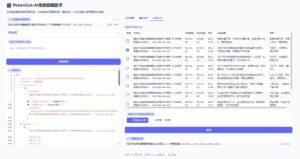
PreenCut 是一款基于 AI 的开源视频剪辑工具,通过语音识别与大语言模型自动分析视频内容,支持自然语言搜索定位片段、智能分段总结、字幕生成与批量剪辑,适合自媒体、课程制作与视频创作者高效提取内容精华。
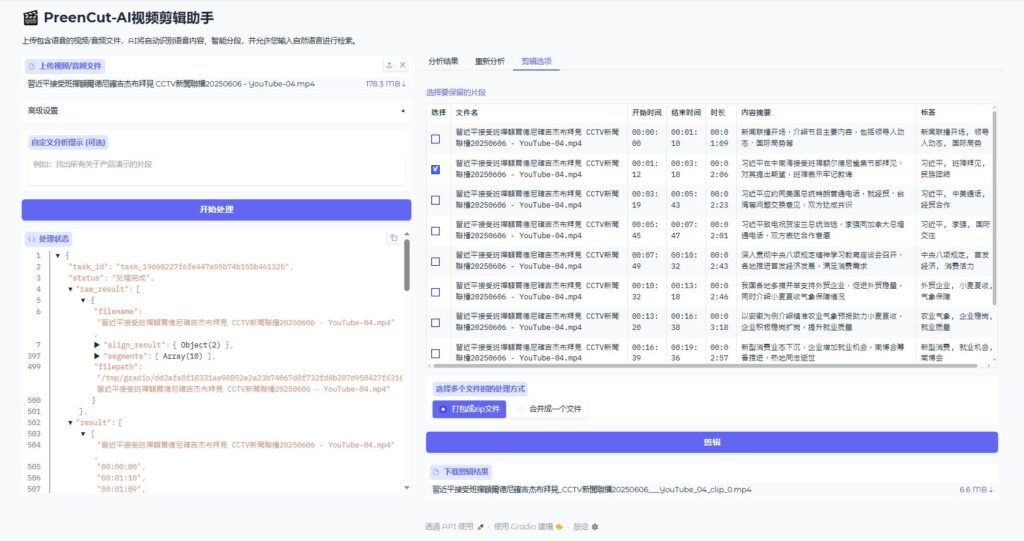
在短视频、自媒体和知识型内容爆发的今天,“从长视频中快速找到有价值片段” 已经成为许多创作者、剪辑师和运营人员的刚需。
传统剪辑方式需要反复拖动时间轴、人工听音频、做标记,不仅耗时,而且极度依赖经验。
最近在 GitHub 上发现了一款非常有潜力的 开源 AI 视频剪辑工具 —— PreenCut,它的核心思路并不是“手动剪视频”,而是:
先让 AI 理解视频内容,再用自然语言告诉它你要剪什么。
这种工作方式,对内容创作者来说简直是效率上的质变。
PreenCut 是一款基于 语音识别 + 大语言模型(LLM) 的智能视频剪辑工具。
它可以自动分析视频或音频内容,将语音转成文字,再通过 AI 对内容进行语义理解、分段和总结,最终让用户用“说话”的方式去找视频片段。
你不需要记住时间点,也不需要一遍遍播放视频,只要输入类似下面的指令:
PreenCut 就会自动帮你定位、筛选并导出对应的视频片段。
PreenCut 使用的是 OpenAI Whisper / WhisperX 语音识别方案,可以将视频中的语音高精度转录为文本,并带有准确的时间戳。
相比传统语音转文字工具,它的优势在于:
对于做课程、播客、访谈、自媒体的用户来说,这一步本身就已经非常有价值。
识别出文字只是第一步,PreenCut 更重要的一点在于 “理解内容”。
它会通过大语言模型(LLM)对转录文本进行分析,实现:
这一步相当于 AI 帮你做了视频大纲 + 内容结构分析,极大降低了理解成本。
这是 PreenCut 最有特色、也是最“AI”的功能之一。
你不再是拖动时间轴,而是可以直接输入自然语言:
PreenCut 会基于语义理解,从整个视频甚至多个视频文件中,自动找出符合描述的片段。
👉 对做课程拆条、短视频二次剪辑、知识切片的人来说,效率提升非常明显。
在找到目标内容后,你可以:
不需要在多个软件之间来回切换,从分析 → 搜索 → 剪辑 → 导出,一条流程完成。
如果你手上有大量素材(例如课程录屏、直播回放、访谈合集),PreenCut 支持:
这对于内容团队、知识付费项目、MCN 机构非常友好。
语音识别往往是最耗时、最吃性能的一步。
PreenCut 支持在 不重新处理音频 的情况下,反复尝试不同的提示词(Prompt)进行分析。
这意味着你可以不断优化查询方式,而不用每次都从头开始,节省大量时间和算力。
PreenCut 采用 本地部署方式,数据不必上传到第三方服务器,隐私和安全性更高。
同时它支持配置多种大模型 API,例如:
这让用户可以根据自己的需求,在成本、速度和效果之间灵活平衡。
官方也给出了一些非常实用的性能优化建议:
faster-whisperwhisperxWHISPER_BATCH_SIZE这些细节对实际使用体验影响很大,也说明这个项目是面向真实使用场景打磨的。
PreenCut 特别适合以下人群:
如果你经常面对 “视频很长,但只需要其中几分钟精华” 的情况,这个工具会非常对胃口。
GitHub 项目地址:
👉 https://github.com/roothch/PreenCut?tab=readme-ov-file
PreenCut 并不是传统意义上的“剪辑软件”,而是一次剪辑思维的升级:
从“我去找内容”,变成“AI 帮我理解内容”。
随着 AI 在内容理解层面的能力不断增强,这类工具未来很可能成为视频创作的标配。如果你对 AI + 视频、自动化剪辑、效率工具 感兴趣,PreenCut 非常值得一试。