Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
本文从软件工程角度系统讲解 Python 爬虫的设计思路与实现方法,帮助开发者构建稳定、可维护、合规的数据采集程序。
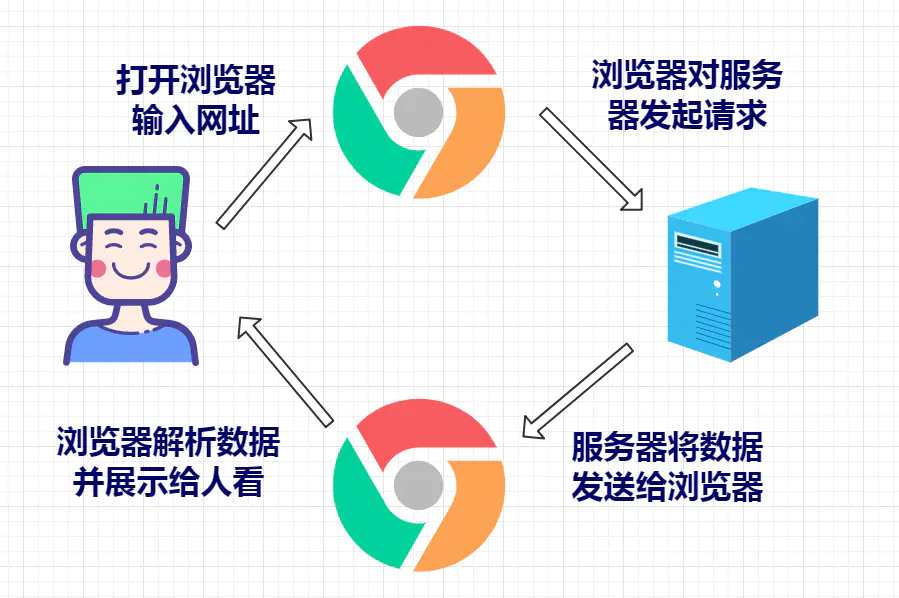
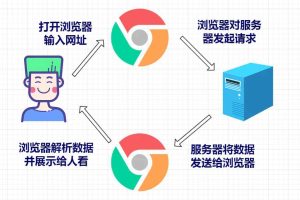
在数据驱动的时代,网页数据采集已经成为许多软件项目的基础能力之一。从价格监控、信息聚合、舆情分析,到内容归档与自动化处理,爬虫技术在实际工程中被广泛应用。
不过,很多初学者学习爬虫时,往往只关注“能不能爬到数据”,却忽略了软件工程中非常重要的几个问题:
本文将从软件工程视角系统讲解:如何使用 Python 编写一个结构清晰、可维护、相对稳定的爬虫程序,并说明在实际项目中需要注意的关键问题。
在众多编程语言中,Python 在爬虫领域非常流行,原因主要有:
Python 代码可读性强,新手也能快速上手。
爬虫开发涉及:
Python 在这些方面都有成熟解决方案。
爬虫往往只是数据链路的一部分,Python 很适合与数据库、Web 服务、任务调度系统集成,构成完整的数据处理流程。
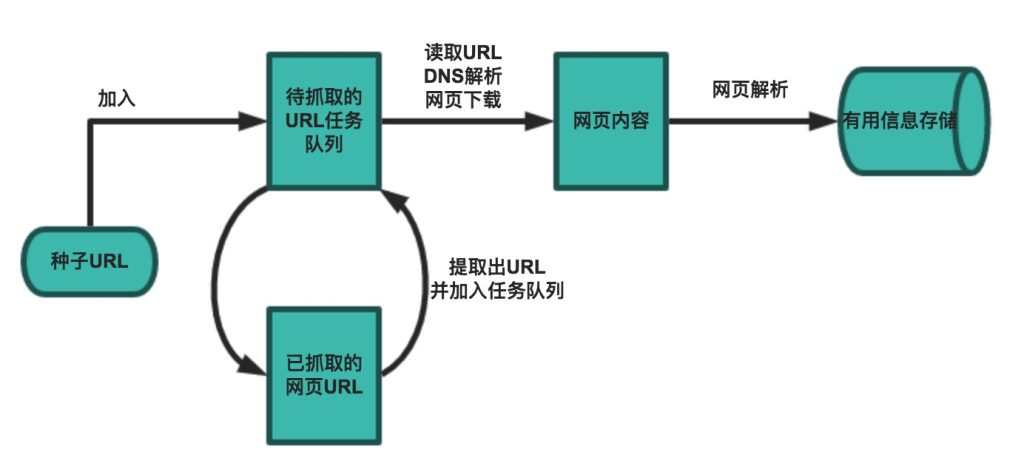
在真实项目中,爬虫不应该只是一个“写在 main.py 里的脚本”,而应该具备基本的软件结构:
spider_project/
├─ main.py # 程序入口
├─ config.py # 配置文件
├─ fetcher.py # 请求模块
├─ parser.py # 解析模块
├─ storage.py # 数据存储模块
├─ scheduler.py # 任务调度
└─ logs/ # 日志目录
这样做的好处是:
从工程角度看,一个爬虫系统通常包含以下步骤:
把这些步骤模块化,是“从脚本进化为程序”的关键一步。
下面给出一个示例级别的爬虫代码片段,用于说明结构思路(非完整生产方案):
import requests
from bs4 import BeautifulSoupdef fetch_html(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
resp = requests.get(url, headers=headers, timeout=10)
resp.raise_for_status()
return resp.textdef parse_title(html):
soup = BeautifulSoup(html, "html.parser")
return soup.title.text.strip()def main():
url = "https://example.com"
html = fetch_html(url)
title = parse_title(html)
print("页面标题:", title)if __name__ == "__main__":
main()
fetch_html:负责网络请求parse_title:负责解析 HTMLmain:负责流程控制这样的分层结构,有利于后期增加:

真实环境中经常出现:
必须加入:
盲目提高并发可能导致:
工程实践中更强调:
把:
统一放入配置文件,避免硬编码,便于后期调整。
爬虫不是目的,数据可用才有价值。
要提前设计:
否则后期数据难以使用。
从软件工程视角看,爬虫不仅是技术问题,更涉及合规与伦理:
合规意识不仅能避免法律风险,也能保证项目长期稳定运行。
在真实项目中,爬虫通常只是数据管道的一环,后面还会连接:
把爬虫当成“可维护的软件组件”,而不是“一次性脚本”,才能在长期项目中真正发挥价值。
爬虫开发不仅仅是“会抓网页”,更是对工程能力的综合训练,包括:
如果你能把爬虫项目当成一个“长期可维护的小系统”来设计,你的软件工程能力会得到非常明显的提升。