Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
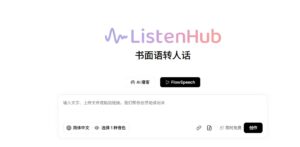
ListenHub 是一款高拟人度 AI 声音生成工具,支持文字转语音、音色克隆、AI 播客、解说视频和 PPT 语音讲解。其 FlowSpeech 技术让语音更自然真实,几乎无法分辨是否为 AI,非常适合自媒体创作者、教育内容生产者和多语言内容需求用户。
老实说,我已经见过不少 AI 语音工具了。
从早期那种「一听就是机器人」的电子音,到后面稍微自然一点,但只要认真听 10 秒,就能判断出不是人。
但这一次,我是真的被 ListenHub 给震住了。
不是那种“还不错”“可以用”的震住,而是那种——
我把生成的语音放给我妈听,她完全没听出来是 AI。
ListenHub 是一款主打「高拟人度 AI 声音生成」的工具,核心能力包括:
官网地址(中文):
👉 https://listenhub.ai/zh
如果只看介绍,你可能会觉得:
“嗯,又一个 AI 配音工具。”
但真正用过之后,你会发现,它和大多数同类产品完全不在一个段位。
ListenHub 最近推出了一个新功能,叫 FlowSpeech。
如果只看名字,你可能没什么感觉,但它真正厉害的地方在于:
它不是在“读文字”,而是在“说话”。
传统 TTS 的逻辑是:
字 → 发音 → 拼起来
ListenHub 的 FlowSpeech 更像是:
字 → 理解意思 → 组织口语 → 再说出来
表现出来的效果是:
很多时候,你甚至能感觉到——
它在“思考”,而不是念稿。
你可以直接丢给它:
它会自动帮你“消化内容”,再用接近真人的方式讲出来。
这对谁最友好?
很多工具也说自己能「克隆声音」,但大多数效果是:
ListenHub 不一样。
你可以:
它就能抓住你的:
然后——
这个声音就可以反复用在视频、播客、配音、TTS 里。
我自己测试的感受是:
这已经不是“能用”的级别了,而是已经开始影响创作方式的那种工具。
很多人低估了 ListenHub,它远不只是「配音」。
你可以把:
直接变成 解说视频。
搭配动态图表 + 讲故事式的讲解,特别适合:
你可以直接用它:
适合:
尤其对不爱露脸的人,简直是救命。
ListenHub 可以直接把:
转换成完整的播客内容。
你可以选择:
对创作者来说,这等于:
一份内容,多种形式,多平台分发。
如果你符合下面任意一条,都非常值得试试:
尤其是:
个人创作者 / 自媒体 / 教育内容 / KOL / 独立开发者
ListenHub 能直接帮你省掉大量时间和精力。
我用过很多 AI 工具,但 ListenHub 给我的感觉是:
以前你要:
现在你只需要:
把内容丢进去,剩下的交给 AI。
而且它生成的效果,已经好到:
不提前说明,真的会被当成真人。
如果你对 AI 配音、内容创作、效率提升感兴趣,
ListenHub 非常值得你花点时间体验一下。
👉 官方地址:
https://listenhub.ai/zh