Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
FlowSpeech 是 ListenHub 推出的情感级 AI TTS 工具,主打“书面语转口语”,可将文章、博客、知识内容一键转为自然流畅的语音,用于播客、视频解说和多平台内容分发,特别适合不想出镜的内容创作者。
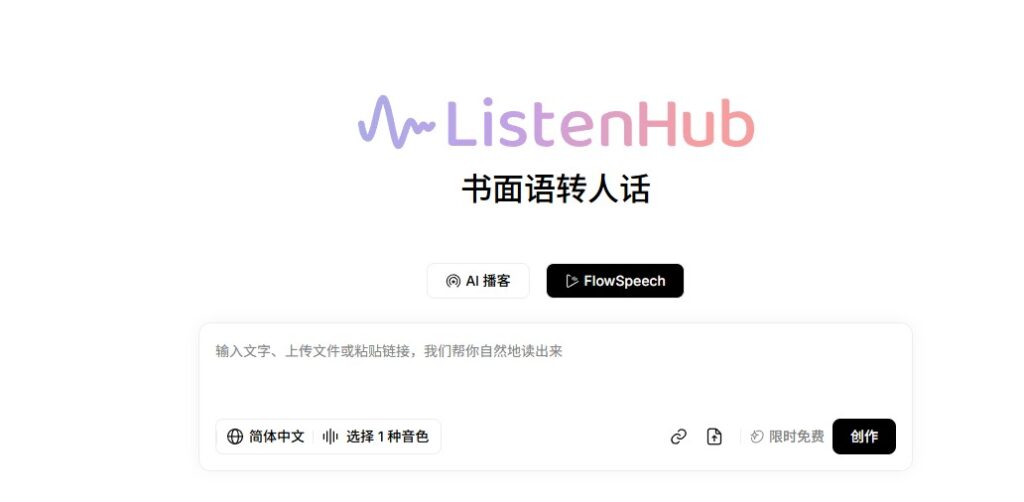
这段时间我密集测试了不少 TTS(文本转语音)工具,说实话,大部分产品都有一个共同问题:
声音标准、清晰,但“没灵魂”。
具体表现就是:
用来读说明文、提示词还行,但一旦涉及博客、知识输出、故事、解说、视频配音,就很容易让人出戏。
直到最近,我在调研过程中发现了 ListenHub 旗下的 FlowSpeech,这是我第一次听到一个 “真的像人在说话”的 TTS。
👉 官方入口:
https://listenhub.ai/zh?tab=flowspeech
简单说一句结论:
FlowSpeech 是我目前用过最接近“真人表达”的 TTS 之一。
它最大的差异点在于一句话:
FlowSpeech 是第一个真正把「书面语 → 口语」这件事做好了的 TTS。
不是简单地把文字“念出来”,而是会根据语义自动调整:
你给它的是一段文章,它给你的不是朗读,而是讲述。
很多人第一次看到 ListenHub,会以为它只是个语音工具,但实际上它更像一个 AI 内容生产中枢。
在一个平台里,你可以做到:
非常适合现在这种:
“一次创作,多端分发” 的内容模式。
有些人就是阅读效率极低,但听觉吸收极强。
看文档犯困,但别人给你讲一遍,你立刻能懂。
这类人用 ListenHub,把:
全部变成音频,效率会直接翻倍。
这类人其实非常多:
ListenHub 非常适合做一个 “过渡工具”:
你先用 AI 把内容“说”出来,反复听,你会慢慢建立对“表达状态”的感觉。
我自己就明显感觉到:
听得多了,说话会更顺。
这个场景我特别认可。
比如你要:
稿子已经写好,但你不知道:
“这样讲出来,听感好不好?”
FlowSpeech 可以在几分钟内帮你 模拟一次完整输出效果,你再根据听感去改稿子,而不是靠想象。
效率差距非常明显。
ListenHub 非常适合做 内容再分发:
一篇内容,可以自然扩展成:
对个人 IP 来说,这是非常友好的放大器。
比如:
你不需要自己出镜、不需要表达,只要把已有内容,用 ListenHub 批量转成可传播素材。
之前就有人分享过:
ListenHub + 数字人 + 带货,一周成交接近百万。
工具本身就是杠杆。
这个场景其实被低估了。
把:
丢进 ListenHub,用你喜欢的声音讲一遍,比死记硬背轻松很多。
尤其适合:
“我需要反复听,才能记住的人。”
这个点可能听起来有点抽象,但确实存在。
当你对某个小众话题:
用 ListenHub 生成对话式内容,某种程度上能缓解这种“表达无处安放”的感觉。
当然,它不能替代真实社交,但作为辅助,是有价值的。
如果你符合以下任意一条:
那 ListenHub + FlowSpeech,非常值得你亲自试一试。
它不是那种“参数一堆但没感觉”的工具,而是真的在解决表达体验问题。




ysyb5o
eb4mhv
yh1tc4
ex8rza
4ltvi9