Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
WaterCrawl 是一款功能强大的开源网页爬虫与数据提取工具,基于 Python 和 Scrapy 构建,支持多语言内容抓取、三种搜索深度、实时进度监控,并可通过 API 与 AI 与自动化平台集成,适合开发者和数据分析场景长期使用。
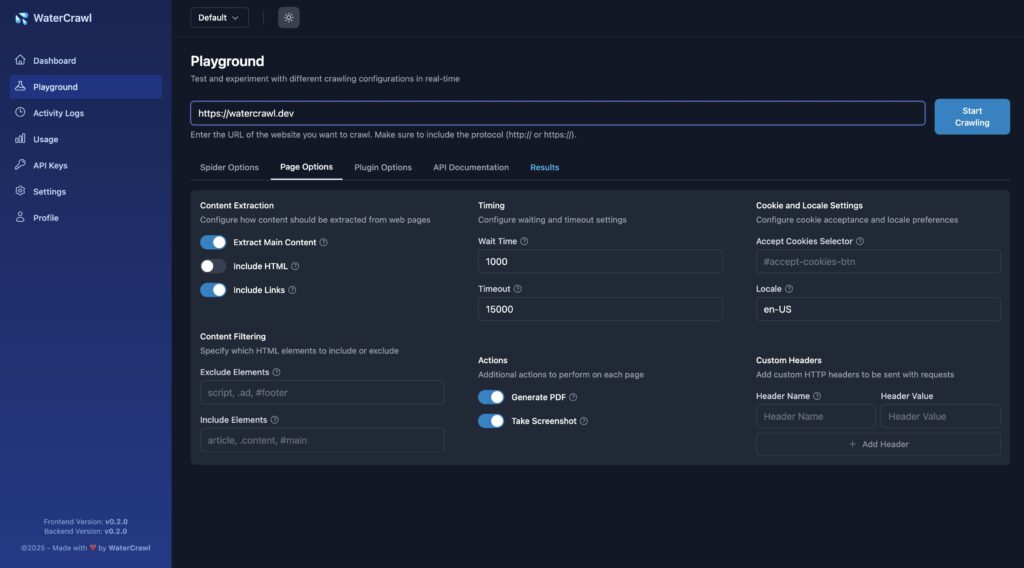
在数据驱动的时代,网页爬虫与数据采集能力已经成为开发者、数据分析师、SEO 从业者以及 AI 应用构建者不可或缺的一项基础能力。无论是做市场调研、内容聚合、竞品分析,还是为大模型准备高质量训练数据,一个稳定、高效、可控的爬虫工具都至关重要。
最近在 GitHub 上发现了一款非常有潜力的开源项目 —— WaterCrawl。它并不是那种“写几个脚本跑一跑”的简单爬虫,而是一套完整的网页爬取与数据提取解决方案,在灵活性、扩展性和工程化程度上都做得相当成熟。
WaterCrawl 是一款基于 Python + Scrapy 构建的开源网页爬虫与数据提取工具,支持高度自定义的网页抓取规则、多语言内容搜索、实时进度监控,并且提供了完整的 REST API,可以非常方便地与 AI 系统或自动化平台集成。
简单来说,它并不只是“爬网页”,而是更像一个 可自托管的数据采集服务平台,你可以把它当作自己的“私有搜索引擎 + 数据抓取中枢”。
项目地址:
👉 https://github.com/watercrawl/watercrawl
WaterCrawl 的核心能力来自于 Scrapy,但在此基础上做了大量工程级封装:
这对于需要长期稳定采集数据的项目非常友好,而不是“一次性脚本跑完就丢”。
WaterCrawl 内置搜索引擎机制,支持三种不同层级的搜索策略:
这使得 WaterCrawl 不再只是“你给 URL 我去爬”,而是可以主动帮你发现内容源。
这是 WaterCrawl 非常亮眼的一点:
例如:
你可以只抓取“日语 + 日本地区”的内容,或者专门分析某一国家的行业信息。
WaterCrawl 使用异步处理架构,并通过 Server-Sent Events(SSE) 实时推送任务状态:
这对于需要跑大规模爬取任务的用户来说,是一个非常重要的工程能力。
WaterCrawl 并不局限于“本地用一用”,它提供了:
目前支持的客户端 SDK 包括:
这意味着你可以非常轻松地把 WaterCrawl 接入到自己的系统中。
WaterCrawl 已经原生支持与以下平台集成:
这让它非常适合用于:
可以说,它本身就是 AI 时代的数据基础设施工具。
对于很多人来说,爬虫最头疼的不是写代码,而是部署和维护。
WaterCrawl 在这方面非常友好:
即使你对 Python 不算特别熟,也可以通过 Docker 很快跑起来。
WaterCrawl 特别适合以下人群:
如果你只是偶尔抓个网页,可能会觉得它“有点重”;
但如果你是 长期做数据采集、内容聚合或 AI 项目,那 WaterCrawl 非常值得重点关注。
总体来看,WaterCrawl 并不是一个玩具级项目,而是一款定位清晰、工程化程度很高的开源网页爬虫与数据提取平台。
它解决的不只是“怎么爬网页”,而是:
如果你正在寻找一款真正适合长期使用的开源爬虫工具,WaterCrawl 是一个非常值得收藏和研究的项目。
项目地址再次放在这里:
👉 https://github.com/watercrawl/watercrawl