Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
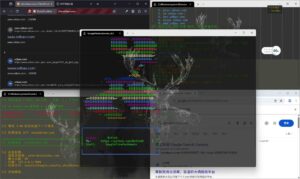
GoogleFirefoxDomain 是一款基于真实浏览器环境的子域名爬取工具,结合 Google 与 DuckDuckGo 搜索引擎,通过 Selenium 自动化模拟人工搜索行为,高效、稳定地收集目标域名的子域名信息,适合安全研究者与渗透测试人员使用。
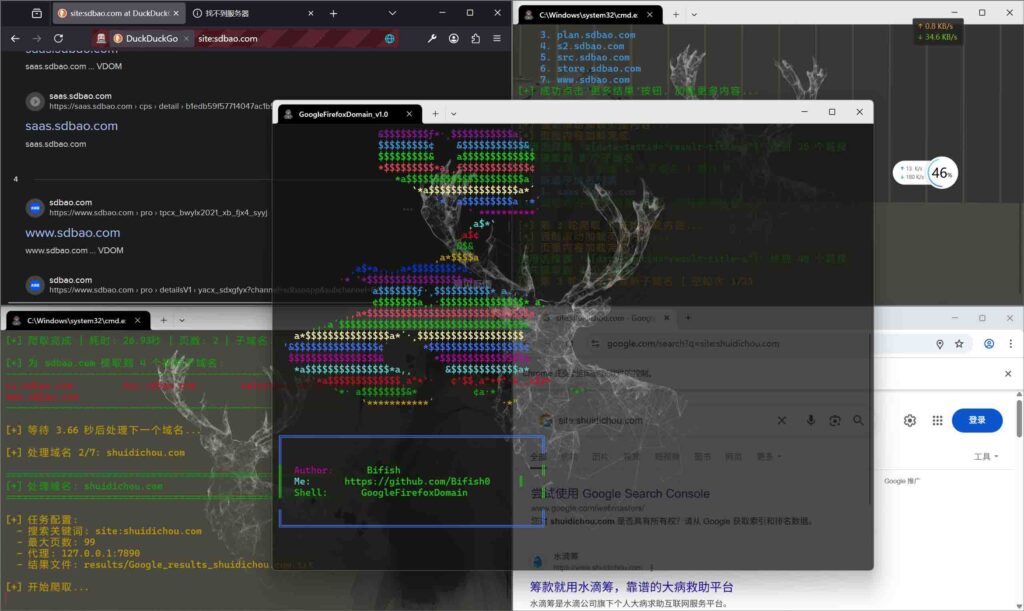
在信息安全测试、资产梳理和漏洞挖掘过程中,子域名收集始终是一个绕不开的重要环节。一个目标域名往往隐藏着大量未被注意的子域,而这些子域中,常常存在配置疏漏或安全风险。
为了更高效地完成这一工作,本文将介绍一款开源工具 —— GoogleFirefoxDomain。
它结合 Google 搜索引擎 + Firefox 浏览器自动化 的优势,能够在真实浏览器环境下稳定爬取子域名信息,非常适合安全研究者与渗透测试人员使用。
GoogleFirefoxDomain 是一款基于 Selenium 自动化框架 开发的子域名爬取工具,通过模拟真实用户的搜索与浏览行为,从搜索引擎结果中提取目标域名的子域名信息。
与传统 API 接口或被动爬虫不同,该工具运行在真实浏览器环境中,具备较强的反检测能力,在实际使用中更加稳定可靠。
项目地址:
👉 https://github.com/Bifishone/GoogleFirefoxDomain
GoogleFirefoxDomain 的最大特点,在于它并非单一脚本,而是由两个互补的核心模块组成:
该脚本主要利用 Google 搜索引擎进行子域名采集,针对搜索结果页结构进行了多重适配,提升稳定性。
主要能力包括:
FirefoxDomain.py 基于 Firefox 浏览器 + DuckDuckGo 搜索引擎,专门优化了搜索结果加载和交互逻辑。
其亮点在于:
很多子域名工具依赖第三方 API 或公开接口,但这些方式存在明显局限:
GoogleFirefoxDomain 使用 真实浏览器 + 模拟人类行为 的方式,具备以下优势:
同时支持 Google 与 DuckDuckGo,避免单一搜索源带来的遗漏。
内置模拟人类浏览行为逻辑,降低触发反爬机制的概率。
爬取结果会自动分类保存到本地文件夹,便于后续分析和整理。
任务完成后可自动发送邮件通知,适合长时间或批量任务。
在网络波动或页面异常情况下自动重试,提高整体成功率。
提供详细的爬取统计信息,方便评估任务效果。
终端信息高亮显示,阅读体验友好。
GoogleFirefoxDomain 并非只适合专业安全团队,也非常适合以下人群:
对于需要真实、全面子域名数据的用户来说,这是一款值得长期保留的工具。
总体来看,GoogleFirefoxDomain 是一款定位清晰、设计务实的子域名爬取工具。
它不依赖复杂的 API,也不过度追求“花哨功能”,而是通过真实浏览器自动化的方式,专注解决子域名收集过程中稳定性与完整性的问题。
如果你正在寻找一款稳定、可控、可二次开发的子域名信息收集工具,那么 GoogleFirefoxDomain 非常值得一试。





https://shorturl.fm/gpnPP
https://shorturl.fm/LsRlJ
https://shorturl.fm/cfNJf
https://shorturl.fm/3axcc
https://shorturl.fm/dOo7D
https://shorturl.fm/7Yfa4