Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
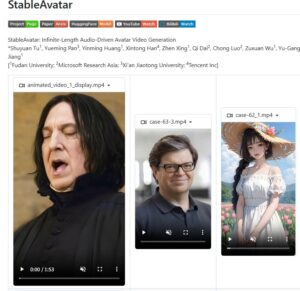
StableAvatar 是一款开源的音频驱动视频生成模型,通过一张参考图片与音频即可生成自然同步、无限时长的说话或唱歌视频。该项目在音频建模与视频扩散结构上进行了创新,有效解决了长视频生成中常见的身份漂移和口型不同步问题,适合虚拟人、AI 主播、数字分身等应用场景。
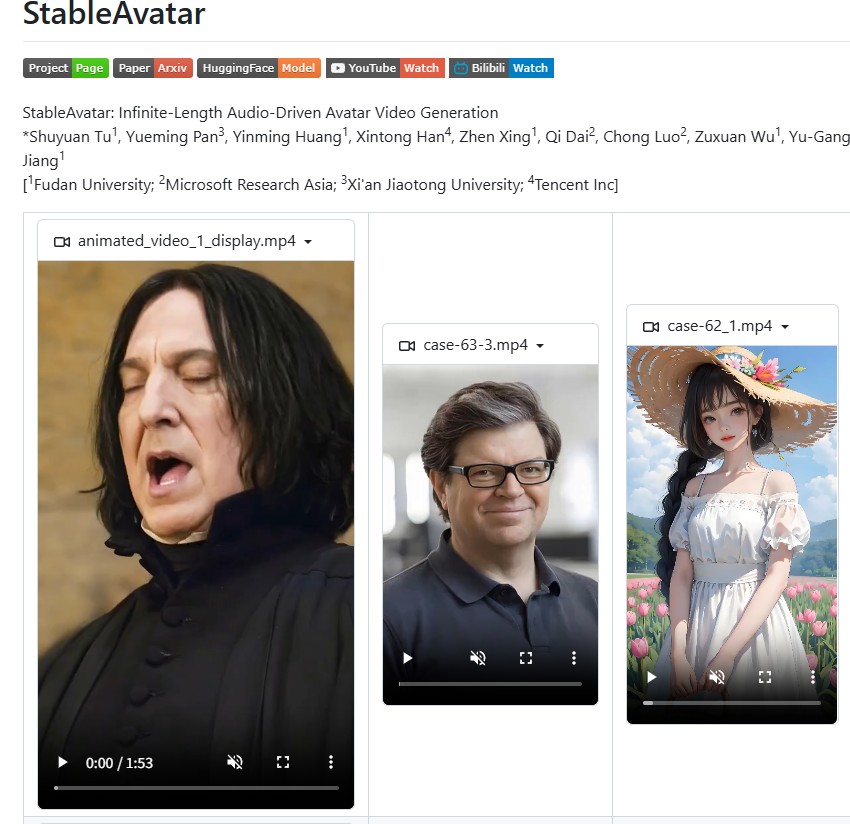
在 AI 视频生成领域,“音频驱动虚拟人视频” 一直是一个非常热门、但同时也非常棘手的方向。
如何让一张静态图片,根据音频内容生成自然说话或唱歌的视频,并且在长时间播放时保持口型同步、人物身份不漂移,一直是学术界和工业界共同面对的难题。
近期,GitHub 上开源的项目 StableAvatar,给出了一个非常有突破性的解决方案。
StableAvatar 是一个端到端的视频扩散 Transformer 模型,能够在无需后期拼接的情况下,生成无限时长的高质量音频驱动视频。
只需要一张参考图片 + 一段音频,就可以生成角色持续说话或唱歌的视频内容,为虚拟人、AI 主播、数字分身等应用提供了新的技术思路。
简单来说,StableAvatar 是一款:
基于音频驱动的视频生成模型,可将静态人物图片与音频结合,生成长时间、自然同步的说话或唱歌视频。
与市面上常见的“对口型”模型不同,StableAvatar 的目标不是只生成几秒钟的演示效果,而是:
这使它在研究价值和工程潜力上,都明显高于许多同类方案。
在理解 StableAvatar 的优势之前,先简单看一下传统方案的问题。
目前大多数音频驱动虚拟人模型,通常采用以下流程:
这种方式在**短视频(几秒)**中还能接受,但在长时间生成时,会出现几个严重问题:
结果就是:
视频越长,同步越差,画面越“崩”。
StableAvatar 针对上述问题,从模型结构和推理机制上做了系统性改进。
这是 StableAvatar 最关键的创新之一。
👉 结果就是:
即使视频持续生成,模型状态依然稳定
在推理阶段,StableAvatar 引入了一种新的引导方式:
这大幅提升了:
为了让无限长度视频在视觉上依然平滑连续,StableAvatar 采用了:
这一步对于“长视频可观看性”至关重要。
虽然 StableAvatar 目前是偏研究型开源项目,但它已经展现出非常广泛的应用潜力。
| 对比维度 | StableAvatar | 传统音频驱动模型 |
|---|---|---|
| 视频时长 | 无限 | 通常 5–10 秒 |
| 身份一致性 | 高 | 易漂移 |
| 音频同步 | 动态引导 | 静态注入 |
| 后期处理 | 不需要 | 依赖拼接 |
| 定位 | 研究级 / 高质量 | 演示级 |
但即便如此,它依然是目前音频驱动视频方向非常值得关注的项目之一。
如果你关注以下方向之一:
那么 StableAvatar 非常值得你收藏和研究。
它并不是“即装即用”的傻瓜工具,而是一个在技术路线层面具有突破意义的项目,代表了音频驱动视频生成向“长视频、稳定、高质量”演进的重要一步。




n81pap