Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
QwenLong-L1.5 是阿里巴巴最新开源的长上下文推理模型,重点提升了超长文本理解、上下文记忆管理与复杂推理能力。相比基线模型,在多项评测中平均提升 9.9 分,适合用于长文档分析、知识问答和智能应用场景。
阿里巴巴最近正式开源了一款面向超长上下文推理与记忆管理的新模型 —— QwenLong-L1.5。
这不是一次简单的模型参数升级,而是一整套**“长上下文推理后训练方案 + 智能体架构 + 记忆机制”**的系统性开源。
如果用一句话来形容它的定位,那就是:
你可以把整本技术手册、完整财报、法律法规文本一次性“丢给模型”,让它在跨章节、跨证据的情况下进行问答、总结、抽取和推理。
在当前的大模型领域,上下文长度已经不再只是“能不能塞进去”的问题。
即便很多模型已经支持 128K、256K 甚至更长的上下文窗口,但在真实场景中仍然面临几个关键挑战:
这意味着,仅靠“把上下文窗口拉长”并不能真正解决问题。
真正困难的,是如何在超过模型物理上下文限制的情况下,让模型持续、稳定地进行推理。
这正是 QwenLong-L1.5 要解决的核心问题。
QwenLong-L1.5 是一个构建在 Qwen3-30B-A3B-Thinking 基础之上的长上下文推理模型。
在基座模型之上,它重点引入了三大关键能力:
换句话说,它不只是“一个模型”,而是:
一套可以被复用、被迁移的长上下文模型训练与推理方法论。
长上下文训练长期面临一个现实问题:
高质量、可验证的训练数据极度稀缺。
很多现有方法仍然停留在所谓的 “needle-in-a-haystack”(大海捞针)任务上,也就是:
但这种任务并不能真实反映复杂文档推理场景。
QwenLong-L1.5 在数据合成层面做了一个关键转变:
具体做法是:
这使得训练数据不再是“碰运气”,而是结构化地逼迫模型学会全局理解与推理。
长上下文训练不仅难,而且极其不稳定。
随着序列长度增长,模型训练中常见的问题包括:
为此,QwenLong-L1.5 引入了多项专门针对长上下文的 RL 策略:
通过控制 mini-batch 中不同任务、不同长度样本的比例,避免训练过程被短序列主导。
这是 QwenLong-L1.5 的一个关键创新点:
这使得模型能够“循序渐进”地适应超长推理,而不是一次性被压垮。
即便模型支持 256K 上下文,它仍然是一个硬上限。
QwenLong-L1.5 的解决方案是引入一套记忆管理框架,让模型具备“持续推理”的能力。
其核心思想是:
这一过程通过 多阶段融合的强化学习范式进行训练,使模型学会:
最终效果是:
模型的可推理范围,远远超过其物理上下文窗口本身。
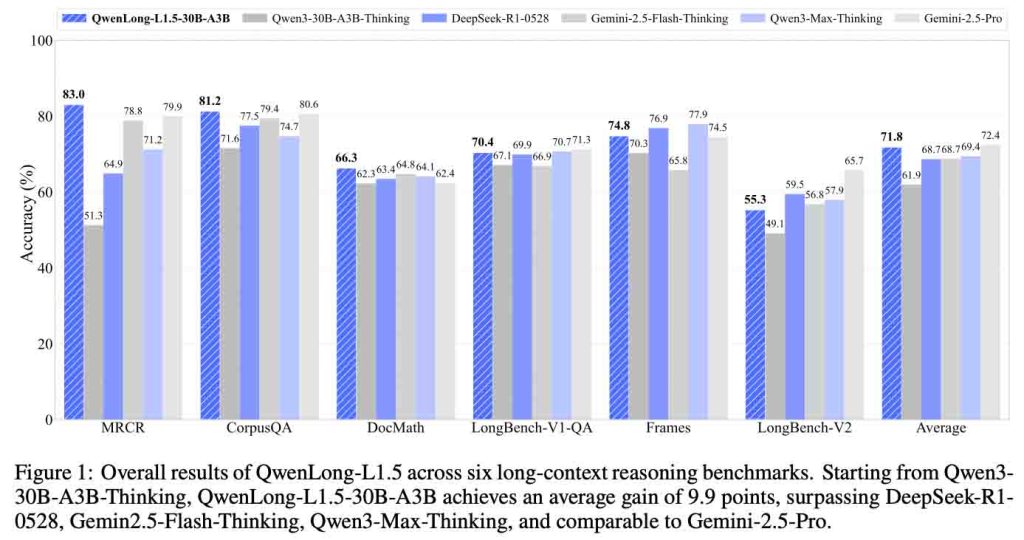
在多个主流长上下文基准测试中,QwenLong-L1.5 相比其基线模型 Qwen3-30B-A3B-Thinking:
更重要的是,这种能力并没有“副作用”。
增强的长上下文推理能力,还显著提升了模型在以下通用任务中的表现:
这说明:
强大的长上下文能力,本身就是通用推理能力的“放大器”。
QwenLong-L1.5 真正有价值的地方,不只是模型权重,而是:
无论你是:
这套方案都具备非常高的学习与落地价值。
GitHub:
👉 https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5