Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
阿里巴巴正式发布 Qwen3-4B-Instruct-2507 与 Qwen3-4B-Thinking-2507 两款新模型,主打小参数高性能,原生支持 256K 上下文。本文全面解析两种版本差异、适用场景及部署价值,适合 AI 开发者与本地模型玩家参考。
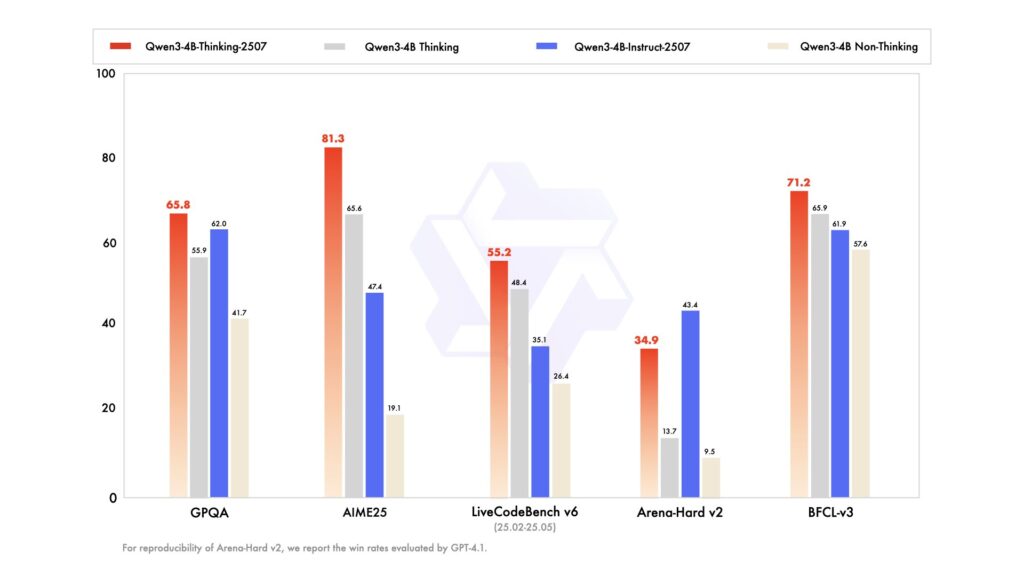
阿里巴巴的开源大模型 Qwen 系列,最近更新频率明显加快。就在不少人还在消化 Qwen3 之前的能力边界时,Qwen3 又悄然上线了两款全新的 4B 级模型,分别是:
别看参数规模只有 4B,这次更新的重点并不在“堆参数”,而是在推理能力、上下文长度以及真实可用性上,堪称是“为落地而生”的一次升级。
这次 Qwen3 的更新并不是简单的小版本迭代,而是明确区分了两种使用场景。
如果你更关注:
那么 Thinking 版本就是为你准备的。
相比普通 Qwen3-4B,它在训练中更强调 Chain-of-Thought(思维链) 和推理过程的稳定性,在处理复杂问题时更“像人在思考”,而不是简单给答案。
适合场景包括:
而 Instruct 版本则是一个更加“均衡”的选择:
如果你是拿模型来做:
那么 Qwen3-4B-Instruct-2507 会更合适。
可以理解为:
👉 Thinking 偏深度推理
👉 Instruct 偏广泛应用
这次更新中,一个非常值得单独拎出来说的点是:
两个模型都原生支持 256K 的上下文长度(262,144 tokens)
这意味着什么?
而且这是 原生支持,不是靠外挂 tricks 或裁剪方案实现的,对开发者来说非常友好。
在 4B 这个参数量级里,256K 上下文已经属于相当激进的配置,非常适合:
从参数结构上看,两者几乎一致,差别主要体现在训练目标与推理能力的侧重。
过去一年,很多人被“百亿、千亿参数”吸引,但现实是:
而 4B 级模型正好处在一个非常舒服的区间:
Qwen3 这次更新,本质上是在告诉开发者:
不是所有问题都需要超大模型,小模型 + 好训练,同样能打。
如果你是下面这些人之一,这两个模型都非常值得收藏:
尤其是 Thinking 版本,在同参数量级里,推理能力已经非常有竞争力。
官方 Hugging Face 地址(建议收藏):
Qwen3 这次的更新,虽然看起来“只是 4B”,但实际上非常务实:
如果你正在寻找能真正用起来的开源模型,而不是单纯看榜单,这一波 Qwen3 新模型,值得你认真看一眼。