Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

有趣分享
有趣分享
一个自媒体平台的爬虫 ,能抓所有公开信息
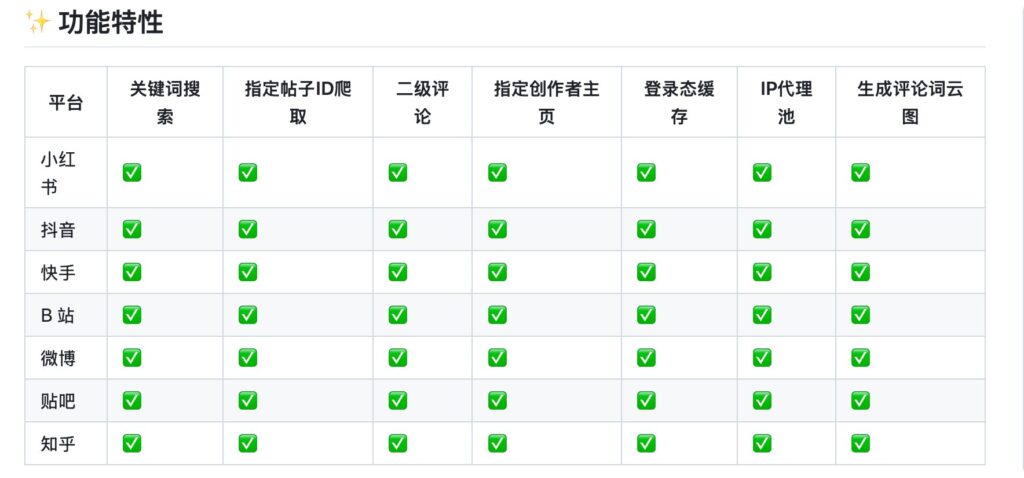
来一个自媒体平台的爬虫 ,能抓所有公开信息
MediaCrawler – 开源免费 – 好像国内所有的社媒都支持了
亮点
• 支持多平台内容采集,包括小红书、抖音、快手、B站、微博、贴吧、知乎等主流平台的公开信息抓取
• 基于 Playwright 浏览器自动化,无需 JS 逆向,技术门槛低
• 数据可存储为 MySQL、CSV、JSON,满足多种数据分析需求
• 支持多账号、IP代理池(Pro 版本),适合大规模采集场景
• 断点续爬、全平台评论抓取,功能完善
• 代码结构清晰,适合学习爬虫架构设计
• 开源免费,适合技术学习和研究,禁止商业及非法用途
要发表评论,您必须先登录。




pgjkhx
4iudr0
9amly1